
Qwen2-Math
Qwen2-Math 简介
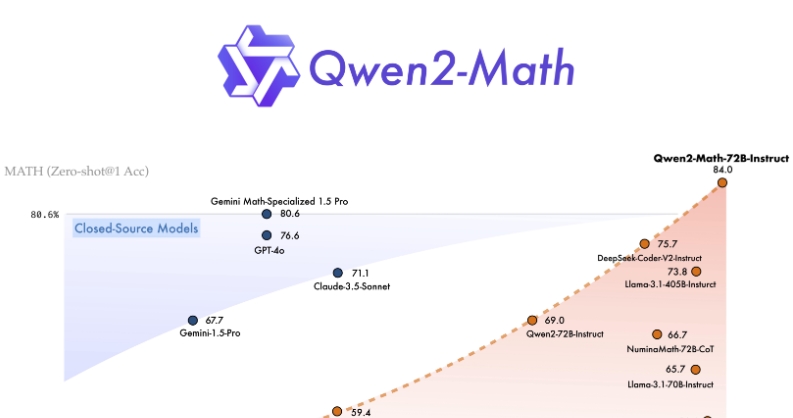
Qwen2-Math 是我们在 Qwen2 系列大语言模型基础上专门研究和增强的数学推理能力的模型系列。我们发布了包括 Qwen2-Math-Instruct-1.5B、7B 和 72B 在内的多种模型版本。Qwen2-Math 显著优于现有的开源和闭源模型(例如 GPT-4)在数学能力方面的表现。Qwen2-Math 旨在通过解决需要复杂、多步骤逻辑推理的高级数学问题,为科学界做出贡献。
使用场景
Qwen2-Math 主要适用于以下场景:
- 数学题解求解:对于各类数学问题进行解答,包括从初等数学到高等数学。
- 教育辅助:为学生和教师提供解题步骤和思路,方便教学和学习。
- 研究支持:协助数学研究人员进行复杂数学问题的推理和计算。
- 竞赛准备:帮助学生准备数学竞赛如数学奥林匹克、AIME 等。
部署和使用
- Hugging Face Transformers:可以在 Hugging Face 平台上部署和推理 Qwen2-Math 模型。示例如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2-Math-7B-Instruct"
device = "cuda"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Find the value of $x$ that satisfies the equation $4x+5 = 6x+7$."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
- ModelScope 平台:建议中国大陆用户使用 ModelScope 平台,因为其支持更快的模型检查点下载。
性能表现
Qwen2-Math 模型在多个英语和中文数学基准测试上的表现优异,例如 GSM8K、Math、MMLU-STEM,以及 CMATH、高考数学填空题和高考数学 QA 等。并且,在复杂数学竞赛评估如 AIME 2024 和 AMC 2023 中也表现出色。
Qwen2-Math 系列不仅在零样本设定中取得了卓越成绩,尤其是在 1.5B 和 7B 模型中 Math 奖励模型的使用使得性能更加突出。
总结
Qwen2-Math 为解决复杂数学问题提供了强大的工具,适用于教育、研究和竞赛准备等多种场合。我们期待 Qwen2-Math 为数学推理和问题解决领域带来更多的创新和突破。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621