
Phi-Mamba
Phi-Mamba简介
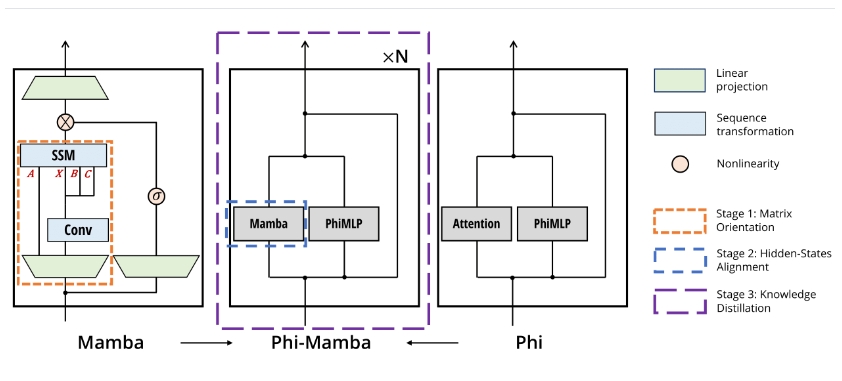
Phi-Mamba是一种基于Mamba的子二次模型,采用MOHAWK方法从Phi-1.5模型中提取知识,训练数据量仅为30亿个tokens。MOHAWK方法使得在跨架构的蒸馏过程中,可以将Transformer视为序列变换,与状态空间模型(SSMs)进行对齐。MOHAWK包含三个阶段,逐步扩大蒸馏的范围:首先从每层的矩阵混合器开始,然后到每层的隐状态,最后是整个模型。
使用场景
-
语言模型构建:Phi-Mamba可用于创建改进的语言模型,替代Phi-1.5中的自注意力机制,提升性能。
-
定制蒸馏:研究人员可以利用Phi-Mamba块返回中间状态,以便进行自定义的MOHAWK阶段蒸馏,甚至可以在其他教师模型上运行MOHAWK。
-
矩阵混合:其独特的矩阵混合器结构适用于需要处理序列数据的任务,如自然语言处理和时间序列分析。
-
评估与基准测试:可使用现有的评估工具,对Phi-Mamba在各类任务(如语言理解和生成)中的表现进行零-shot evaluations,适用于学术研究和工业应用。
Phi-Mamba的设计旨在提升模型的计算效率和性能,适合需要高效处理大规模数据的应用场景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621