
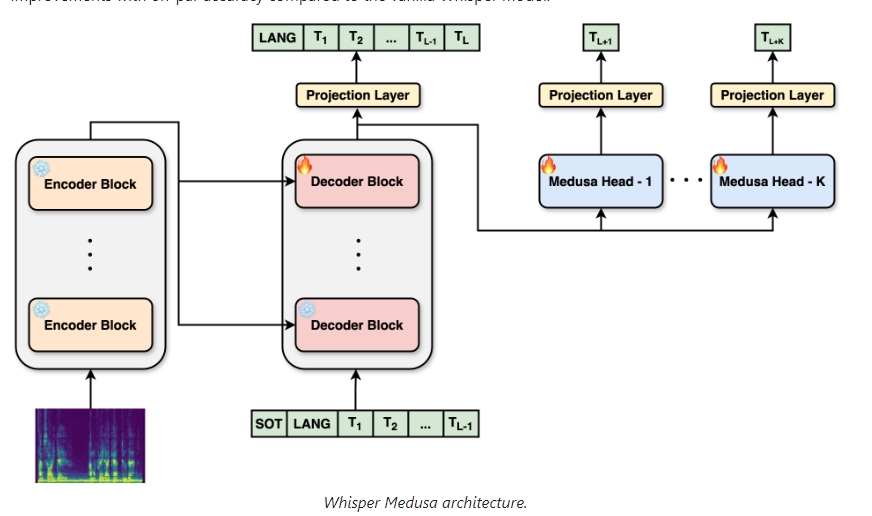
Whisper Medusa
Whisper Medusa是基于Whisper模型的一种高级编码器-解码器模型,用于语音转录和翻译。通过在每次迭代中预测多个标记(tokens),Whisper Medusa显著提高了推理速度,同时只带来少量的词错误率(WER)下降。模型在LibriSpeech数据集上进行训练和评估,表现出强大的速度和准确性。
使用场景
Whisper Medusa主要应用于以下场景:
- 语音转录:将音频文件转录为文本,对语音识别任务提供高效解决方案。
- 实时语音翻译:在国际会议或多语言交流场景中,提供实时的语音翻译服务。
- 自动字幕生成:为视频内容自动生成字幕,提高内容的可访问性。
- 语音助手:增强语音助手的自然语言理解和响应速度。
安装步骤
- 创建并激活虚拟环境:
conda create -n whisper-medusa python=3.11 -y
conda activate whisper-medusa
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
- 安装Whisper Medusa包:
git clone https://github.com/aiola-lab/whisper-medusa.git
cd whisper-medusa
pip install -e .
使用方法
以下是一个简单的推理代码示例:
import torch
import torchaudio
from whisper_medusa import WhisperMedusaModel
from transformers import WhisperProcessor
model_name = "aiola/whisper-medusa-v1"
model = WhisperMedusaModel.from_pretrained(model_name)
processor = WhisperProcessor.from_pretrained(model_name)
path_to_audio = "path/to/audio.wav"
SAMPLING_RATE = 16000
language = "en"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input_speech, sr = torchaudio.load(path_to_audio)
if sr != SAMPLING_RATE:
input_speech = torchaudio.transforms.Resample(sr, SAMPLING_RATE)(input_speech)
input_features = processor(input_speech.squeeze(), return_tensors="pt", sampling_rate=SAMPLING_RATE).input_features
input_features = input_features.to(device)
model = model.to(device)
model_output = model.generate(input_features, language=language)
predict_ids = model_output[0]
pred = processor.decode(predict_ids, skip_special_tokens=True)
print(pred)
模型评估
可以通过提供包含音频文件路径、对应的转录文本及语言的CSV文件来评估模型:
python whisper_medusa/eval_whisper_medusa.py \
--model-name /path/to/model \
--data-path /path/to/data \
--out-file-path /path/to/output \
--language en

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621