
DiffPPO
DiffPPO概述
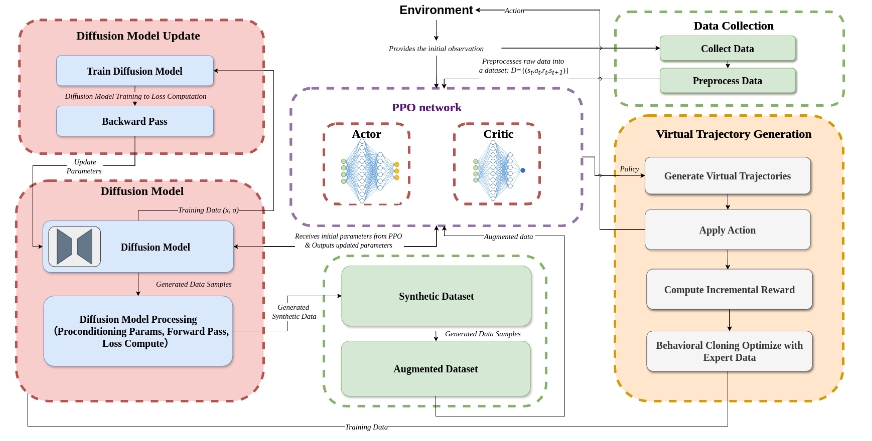
DiffPPO是一种将扩散模型与近端策略优化(PPO)相结合的强化学习框架,旨在提高样本效率和探索能力。该框架在robomimic平台上实现,并使用D4RL数据集进行实验,结果表明在数据有限的环境下具有明显的性能提升。
使用场景
DiffPPO适用于以下场景:
- 样本效率要求高的任务:在数据采集成本高昂或数据有限的环境中,DiffPPO通过生成合成轨迹来提高学习效率。
- 需要增强探索的强化学习问题:当环境复杂且难以探索时,DiffPPO能够利用扩散模型提升策略探索能力,从而更好地发现最优策略。
- 模拟和训练机器人等智能体:在需要快速训练并高效学习的自动化或机器人控制领域,DiffPPO展现了其潜力。
总结来说,DiffPPO通过有效结合扩散模型和PPO算法,为强化学习领域带来了更高效的数据使用和更深入的环境探索能力。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621