
Emu3
Emu3简介
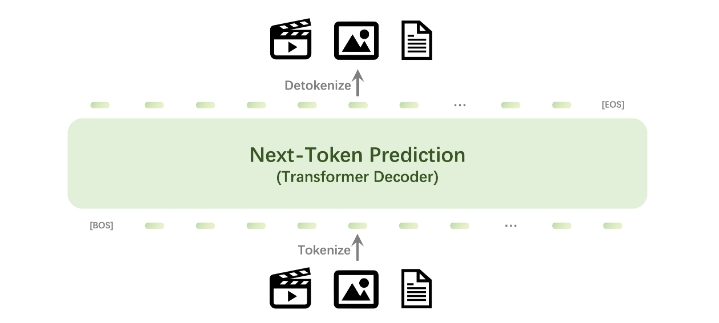
Emu3是一种先进的多模态模型套件,专注于通过下一个标记预测(next-token prediction)进行训练。该模型通过将图像、文本和视频标记化为离散空间,采用单个变换器从头开始训练,以处理多模态序列的混合。Emu3在生成和感知任务上表现优异,超越了许多著名的任务特定模型,如SDXL、LLaVA-1.6和OpenSora-1.2,同时避免了扩散或组合架构的复杂性。
Emu3的突出特点包括:
- 图像生成:能够根据文本输入生成高质量的图像,仅需预测下一个视觉标记,支持灵活的分辨率和风格。
- 视觉语言理解:对物理世界的理解能力强,能够生成连贯的文本响应,且不依赖于CLIP或预训练的大语言模型(LLM)。
- 视频生成:通过预测视频序列中的下一个标记来因果生成视频,能够自然地扩展视频并预测接下来的事件。
使用场景
- 图像生成:适用于需要根据文本描述生成高质量图片的应用场景,如游戏设计、广告创意等。
- 视觉理解:可以用于图像描述、产品图像的自动注释等任务,支持帮助盲人识别场景或物体。
- 视频内容创作:适用于创建短视频、动画等,能够根据上下文自动生成视频片段,极大地提高了创作效率。
- 多模态交互:提高AI在多模态交互中的表现,实现更自然的用户体验,例如在智能助手中进行复杂的视觉与语言互动。
通过此模型,用户能够在多种应用场景中实现更智能、更高效的内容生成与理解。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621