
LongLLaVA
LongLLaVA 简介
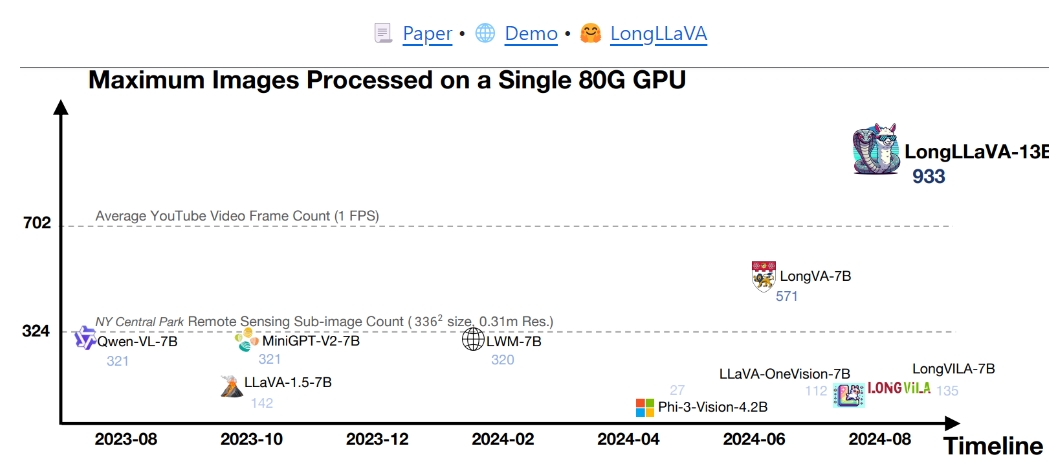
LongLLaVA是一种高效的多模态大型语言模型(LLM),旨在通过混合架构扩展处理高达1000幅图像的能力。其设计灵感来源于GPT-4V,并得到了视觉指令调优(Visual Instruction Tuning)的支持。LongLLaVA采用了分阶段的训练方法,包括单幅图像的对齐、单幅图像的指令微调以及多幅图像的指令微调,以提升模型的多模态理解和响应能力。
使用场景
LongLLaVA具有广泛的应用场景,包括但不限于:
- 图像描述生成:为大量图像生成连贯的自然语言描述。
- 视觉问答:用户可以根据上传的多幅图像提出问题,LongLLaVA将提供基于图像内容的准确回答。
- 教育和培训资源:可用于创建图文并茂的教学材料,帮助学习者更好地理解复杂主题。
- 内容创作:支持生成图文结合的创意内容,如故事、插画描述等。
- 多媒体内容分析:针对视频或多张图片的分析,提供更深刻的理解和解读。
总体而言,LongLLaVA通过其高效的架构和多模态能力,能够在多个领域中提升信息检索、用户交互和内容生成的效率和质量。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621