
Spider 2.0
Spider 2.0 概述
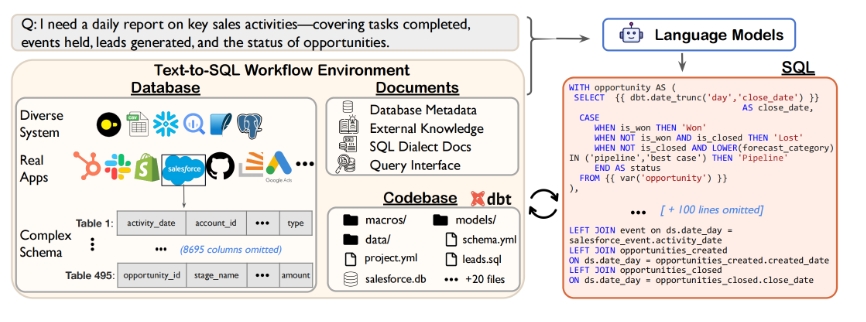
Spider 2.0 是一种新基准,旨在评估大型语言模型(LLMs)在复杂企业级文本到 SQL(Text-to-SQL)工作流中的性能。与之前的 Spider 1.0 和其他相关基准相比,Spider 2.0 面临着更大的挑战,包括更复杂的数据环境(如超过3000列)、多种 SQL 方言(如 BigQuery、Snowflake)和不同类型的操作(如数据转换和分析)。尽管现有的先进模型,如 GPT-4,在 Spider 1.0 的任务中有 86.6% 的成功率,但在 Spider 2.0 中仅为 6.0%,显示出这一基准的难度。
使用场景
Spider 2.0 的主要使用场景包括:
-
企业级数据分析:适用于需要复杂 SQL 查询的企业环境,可以帮助用户通过自然语言提问生成相应的 SQL 代码。
-
自然语言处理研究:为研究人员提供一个评估和比较不同自然语言处理模型性能的平台,以推动文本到 SQL 转换技术的发展。
-
自动化报告生成:在数据报告和分析软件中,用户可以通过自然语言询问数据,从而自动生成所需的 SQL 查询并获得分析结果。
-
教育和培训:用于帮助学生和从业者学习 SQL 查询构建,理解文本到 SQL 转换的原理和应用。
Spider 2.0 的设计旨在提升 LLM 在处理复杂企业查询场景下的能力,同时为开发者提供了完整的评估框架和工具,使其能够在各种数据库系统上进行有效的 SQL 查询生成和执行。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621