
VITA
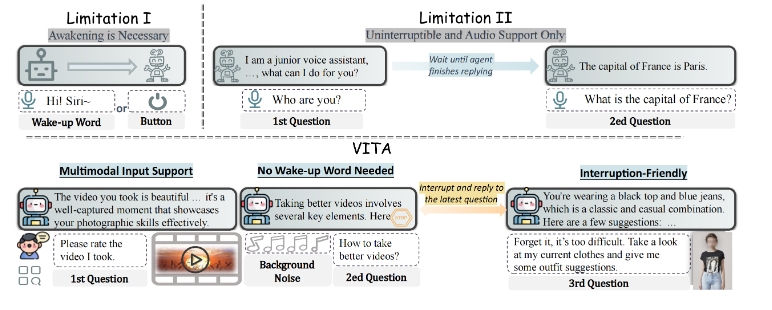
VITA是首个开源的互动全模态大语言模型(Multimodal Large Language Model,MLLM),能够同时处理和分析视频、图像、文本和音频等多种模态,旨在提升用户的互动体验。VITA的设计有三个关键特点:一是具有全面的多模态理解能力,能够在多种语言和视听内容上表现出色;二是支持无唤醒词的互动,用户可以直接提问而无需特殊指令;三是引入音频中断互动功能,用户可以随时通过语音提问,VITA会及时响应。
使用场景
VITA的应用场景非常广泛,包括但不限于:
- 虚拟助手:可以用于构建智能助手,能够理解用户的语音和视觉信息,实现更自然的人机交互。
- 教育工具:帮助学生通过图像和音频互动学习,例如提供即时反馈和解答。
- 内容创作:为创作者提供灵感和建议,通过多模态内容生成来支持视频制作或多媒体项目。
- 无障碍项目:为语音和视觉障碍人士提供服务,通过图像分析和语音理解改善信息获取的便利性。
总之,VITA的灵活性和多模态理解使其在多个领域都具备了巨大的应用潜力。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621