
VisionTS
VisionTS 概述
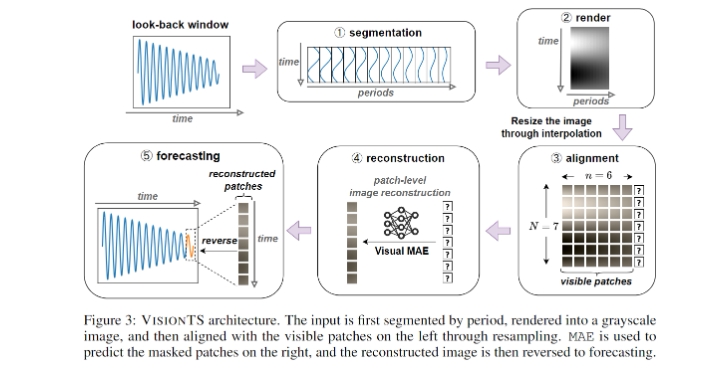
VisionTS 是一种基于视觉掩码自编码器(Visual Masked Autoencoders)的时间序列预测(TSF)基础模型。与当前的时间序列预测模型(如文本或时间序列为基础的模型)不同,VisionTS 从丰富的高质量自然图像中构建,表现出与现有方法相当的甚至更优的性能,且不需要对时间序列数据进行任何适配。它通过将时间序列预测任务重新定义为图像重建任务,利用图像重建的方式进行处理。
使用场景
VisionTS 适用于多种时间序列预测的应用场景,包括但不限于:
- 无监督学习:可以进行零-shot 时间序列预测,适合在未标注数据上进行预测。
- 长期时间序列预测:适配于长期时间序列数据的分析,能够为商品销售、交通流量等提供准确的预测。
- 科研与实验:作为基础模型,学术界和工业界可以使用 VisionTS 来解决各种时间序列预测的研究问题。
- 数据可视化:通过图像重建,可以进行直观的结果可视化,帮助理解预测的过程和结果。
VisionTS 为时间序列预测提供了新的思路和方法,特别是在需要处理大量无标注数据时,展现出其独特的优势。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621