
localGPT-Vision
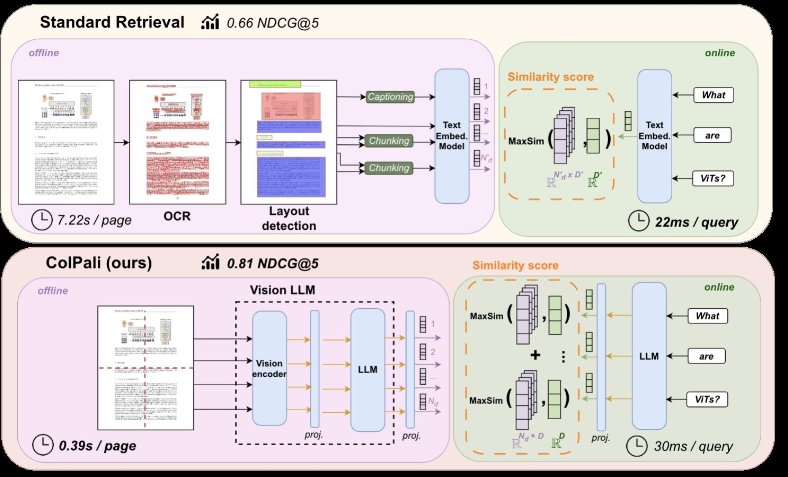
localGPT-Vision 是一款基于视觉的端到端检索增强生成(Retrieval-Augmented Generation,RAG)系统。用户可以上传和索引文档(包括 PDF 和图像),针对内容提出问题,并获得响应及相关文档片段。该系统利用 Colqwen 或 ColPali 模型进行检索,然后将检索到的页面传递给视觉语言模型(Vision Language Model,VLM)以生成回答。
主要特点
- 端到端视觉检索:结合视觉文档检索与语言模型,提供全面的答案。
- 文档上传与索引:支持上传 PDF 和图像,使用 ColPali 进行索引。
- 聊天接口:用户可以在对话式界面中询问与上传文档相关的问题。
- 会话管理:可以创建、重命名、切换和删除聊天会话。
- 模型选择:支持多种视觉语言模型,如 Qwen2-VL-7B-Instruct、Google Gemini 和 OpenAI GPT-4 等。
- 持久索引:索引数据保存在磁盘上,可以在应用重启时加载。
使用场景
localGPT-Vision 适合多个场景,包括但不限于:
- 学术研究:研究人员可以上传相关文献,快速提取信息、总结观点。
- 企业文档管理:企业可以将大量文档上传并检索出关键信息,提高工作效率。
- 教育及培训:教师可以上传教材资料,学生可通过提问获取具体学习内容。
- 法律审查:律师可以上传案件文件,快速检索相关法律条款和判例。
- 产品说明和手册:用户可以查询产品手册中的具体操作步骤或故障排除方法。
localGPT-Vision 的强大功能能够显著提升信息检索和获取的效率,适合需要处理大量文档内容的用户。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621