
Fashion-VDM
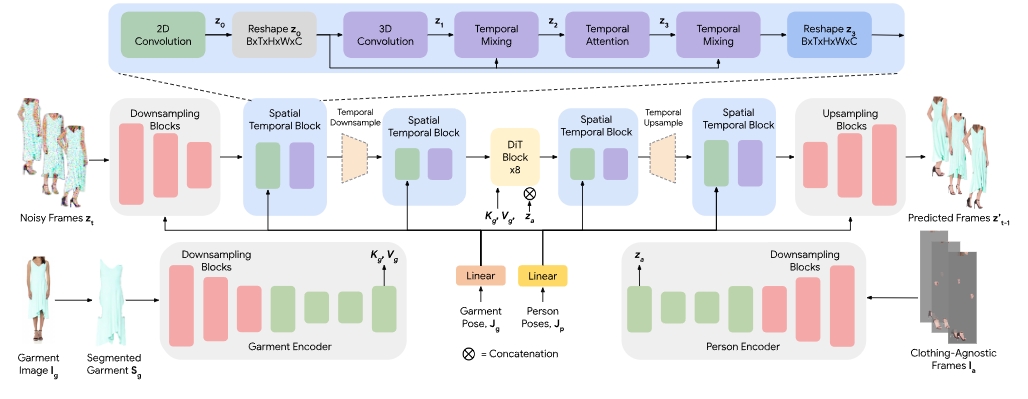
Fashion-VDM是一种用于生成虚拟试穿视频的视频扩散模型(VDM)。该模型的主要目标是结合输入的服装图像和个人视频,生成高质量的试穿视频,同时保持人的身份和动作。虽然基于图像的虚拟试穿已经取得了显著成果,但现有的视频虚拟试穿方法在服装细节和时间一致性方面仍显不足。因此,Fashion-VDM提出了一种基于扩散的架构,采用分类器无关引导策略以增加对条件输入的控制,并采用渐进式的时间训练策略,以实现单次处理64帧、512像素的视频生成。
该模型的架构通过对噪声视频进行处理,提取人物姿态和不依赖于服装的帧。服装图像也经过处理以提取服装分割和服装姿态。在训练过程中,Fashion-VDM经历了多个逐步增加帧长度的阶段,先对图像模型进行预训练,然后再针对视频数据集进行时空层的训练。
此外,Fashion-VDM还引入了分割分类器无关引导策略,使其能够对多个条件信号进行独立控制。最终的实验显示,这种方法在视频虚拟试穿领域设置了新的最先进记录。
尽管Fashion-VDM在生成虚拟试穿视频方面表现出色,但模型仍存在一些局限性,比如可能出现的身体形态不准确、伪影和服装遮挡区域的不正确细节等。未来的工作可能会考虑多服装条件和个体化定制,以提高服装和人物的一致性。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621