
Grounded-VideoLLM
Grounded-VideoLLM简介
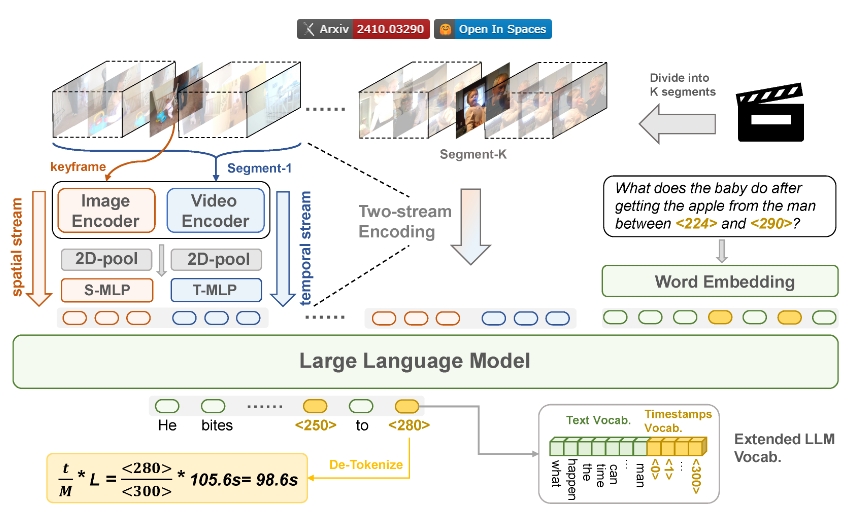
Grounded-VideoLLM是一个专注于细粒度时间定位的多模态视频大语言模型。该模型不仅擅长时间句子定位、密集视频字幕生成和基于视频的问答等任务,还展现出作为视频理解助手的广泛潜力。Grounded-VideoLLM通过引入额外的时间流以编码帧之间的关系、特定时间知识的离散时间令牌,并采用多阶段训练方式(从简单的视频字幕任务逐步过渡到复杂的时间定位任务),有效提升了模型的时间推理能力。
使用场景
- 时间句子定位:在视频中找到与特定文本描述对应的时间段,适用于对视频内容进行精细分析和标注。
- 密集视频字幕生成:为视频生成详细且准确的字幕,适合新闻报道、教育视频等内容丰富的场景。
- 基于视频的问答(VideoQA):用户可以就视频内容提出问题,模型能够提供基于视频信息的准确回答。
- 视频理解的通用助手:在需要对视频进行分类、总结或分析的应用中,Grounded-VideoLLM可作为智能辅助工具,提升人机交互的效率。
该模型的应用范围广泛,包括教育、媒体监控、内容审核等领域,能够帮助用户更好地理解和利用视频信息。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621