
Mooncake
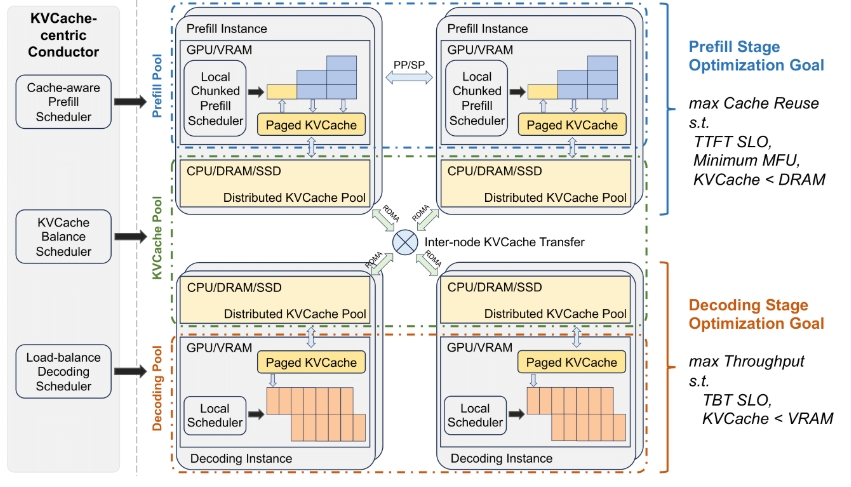
Mooncake 是一种以 KVCache 为中心的解耦架构,专为大型语言模型(LLM)服务而设计。它是由 Moonshot AI 提供的领先 LLM 服务 Kimi 的服务器平台。Mooncake 的核心组件是 Transfer Engine,最近已开源,提供高效、可靠和灵活的数据传输支持,适用于多种协议,包括 TCP 和 RDMA。
Mooncake 的特点
- 解耦架构:将预填充和解码集群分离,充分利用 GPU 集群中未充分利用的 CPU、DRAM 和 SSD 资源,以实现高效的 KVCache。
- 调度器:通过 KVCache 中心调度器,优化整体吞吐量且满足延迟相关的服务水平目标(SLO)。
- 高效性:在面对高负载场景时,Mooncake 采用预测性早期拒绝政策,能够在长上下文场景中提升吞吐量,部分情况下可实现最多 525% 的吞吐量增长。
使用场景
- 独立使用 Transfer Engine:作为高性能数据传输框架,支持从 DRAM、VRAM 或 NVMe 中传输数据,解决传统 TCP 协议带来的延迟问题。
- P2P Store:适用于在集群内快速有效地共享临时对象(如检查点文件),尤其是在需要数据快速共享的场景中。
- 与 vLLM 集成:优化 LLM 推理过程,支持预填充与解码阶段的解耦,提高多节点间的 KVCache 数据传输效率。
Mooncake 设计旨在提高大规模语言模型服务的效率和响应速度,能够处理更加复杂和高并发的请求场景,是大规模 AI 应用中不可或缺的一部分。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621