
YOPO
YOPO(You Only Prune Once)是一种针对多模态大语言模型(MLLM)的剪枝策略,旨在有效降低视觉计算的资源消耗。传统上,剪枝视觉标记的过程本身需要大量的计算资源,但YOPO提出了一种一次性剪枝的方法,从而简化这个过程。
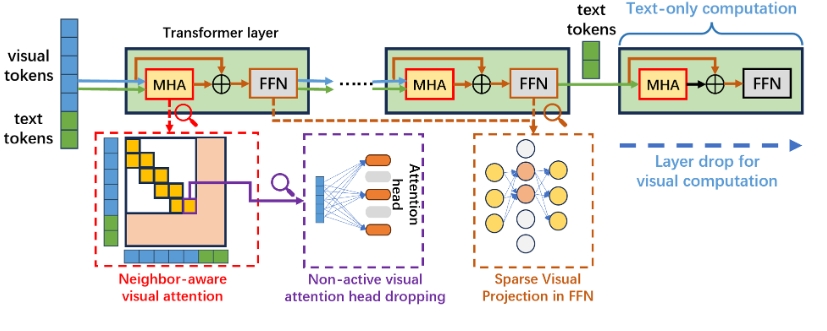
YOPO的核心剪枝策略:
- 邻域感知的视觉注意力计算:仅涉及空间邻近的视觉标记进行计算。
- 非活动视觉注意力丢弃:利用视觉和文本标记之间的注意力权重比,评估注意力头在视觉计算中的重要性,从而剪掉不活跃的神经元。
- 稀疏视觉投影:得益于稀疏的视觉表示,在前馈神经网络(FFN)视觉计算中可丢弃大部分神经元。
- 层级有效计算:在最后几层停止视觉相关计算。
这些方法结合使用,可以有效减少视觉信息处理所需的计算资源,使得模型在保持性能的同时,能够实现更高效的推断和训练。
使用场景:
- 视觉问答与推理:YOPO经过评估在多个视觉问答基准上具有良好的表现,如VQAv2、GQA等。
- 大规模视觉分析:适用于那些需要处理大量视觉数据的应用场景,例如自动驾驶、安防监控等。
- 多模态交互系统:在聊天机器人或智能助手中实现更高效的视觉理解与交互。
YOPO的设计旨在为研究者和开发者提供一种高效的资源管理解决方案,以便能够在计算有限的环境中实现强大的视觉理解能力。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621