
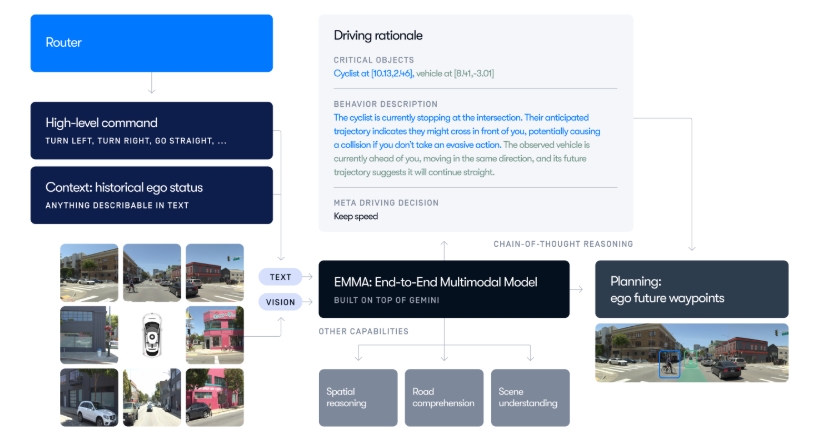
OpenEMMA
OpenEMMA 是一个开源的多模态模型,旨在实现端到端的自主驾驶运动规划。它基于 Waymo 的自主驾驶模型 EMMA,结合了视觉语言模型(VLMs)如 GPT-4 和 LLaVA 的预训练世界知识,整合文本和前视摄像头输入,从而能够精确预测未来的自我路径点,并提供决策的合理解释。OpenEMMA 的目标是为研究人员和开发者提供可访问的工具,以推动自主驾驶研究和应用的发展。
使用场景
OpenEMMA 可用于多个自主驾驶领域的应用场景,包括但不限于:
- 运动规划:通过预测自动驾驶车辆在复杂环境中的未来路径,提高安全性和效率。
- 决策解释:为自动驾驶决策提供清晰的语境和依据,增加系统的可解释性,便于调试和优化。
- 多模态感知:利用图像、文本等多种输入进行数据融合,使系统能够在多变的驾驶环境中做出更为精准的判断。
- 研究与开发:为学术界和工业界的研究者提供一个基础平台,支持不同模型和算法的比较和评估。
通过这些功能,OpenEMMA 旨在为持续改进自主驾驶技术和实现更高安全标准做出贡献。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621