
Dispider
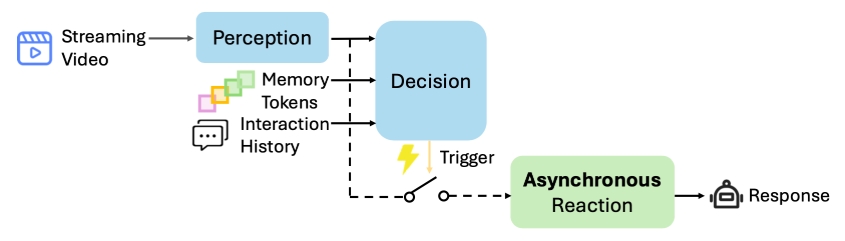
Dispider 是一种新的在线视频大语言模型(LLM),它通过解耦感知、决策和反应模块,实现了实时交互的能力。这一创新使得 Dispider 可以在观看视频的同时与之进行有效互动,适用于例如直播场景中的即时反馈,而传统的视频 LLM 通常需要在处理完所有视频内容后才能给出反应。
主要特点:
- 实时互动:与传统的离线视频 LLM 不同,Dispider 可以在视频流中进行动态、及时的反馈。
- 异步模块:Dispider 将感知、决策和反应分解为异步模块并行运行,这确保了视频处理和响应生成的连续性,避免了阻塞。
- 卓越性能:在诸如 StreamingBench、EgoSchema、VideoMME、MLVU 和 ETBench 等基准测试中,Dispider 的表现优于在线视频 LLM 和离线视频 LLM,特别在时间推理和处理不同视频长度方面表现出色。
使用场景:
- 直播互动:在直播场景中,实时解析视频内容并生成即时的互动反馈,增强用户参与感。
- 教育培训:通过视频培训内容实时提问和反馈,引导学习过程。
- 视频内容分析:分析和理解视频内容,在合适的时机提供解释或评论。
Dispider 的出现为视频处理领域带来了新的可能性,使得对视频内容的理解和互动更加高效和灵活。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621