
LLaVA-Mini
LLaVA-Mini 是一个高效的统一大规模多模态模型,能够以较高的效率理解图像、高分辨率图像以及视频。该模型通过仅使用一个视觉标记来表示每幅图像,从而显著提高了其处理效率,具体体现在以下几个方面:
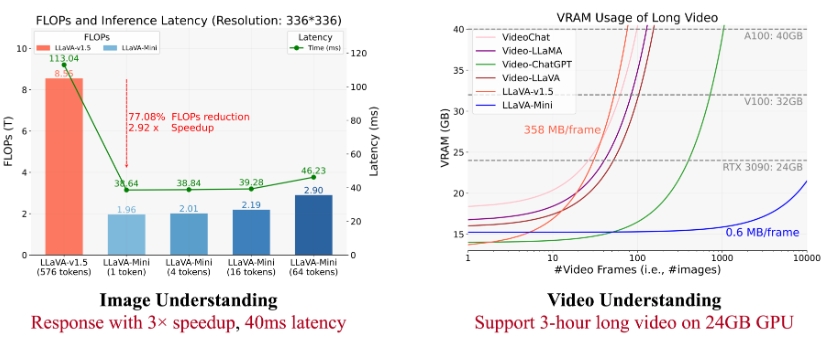
- 计算开销减少:LLaVA-Mini 在处理图像和视频时的计算量下降了 77%。
- 响应延迟降低:从 100 毫秒降至 40 毫秒。
- 内存使用减少:每幅图像的GPU内存使用从 360 MB 减少到 0.6 MB,支持对长达 3 小时的视频进行处理。
LLaVA-Mini 在性能上与 LLaVA-v1.5 相当,但使用的视觉标记数量从 576 降至仅 1,表现出极高的效率。
使用场景
LLaVA-Mini 适用于多个领域,主要包括:
- 图像理解:用户可以使用该模型对特定图像进行分析,例如识别图像中的文字或物体。
- 视频理解:模型能够从视频中提取重要信息,例如描述视频中发生的事件。
- 实时应用:得益于低延迟和高效的计算性能,LLaVA-Mini 可以应用于需要快速反应的实时场景,如监控、自动驾驶等。
总的来说,LLaVA-Mini 以其高效的处理能力和多模态理解能力,为各种智能视觉应用提供了强大的支持。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621