
LatentSync
LatentSync简介
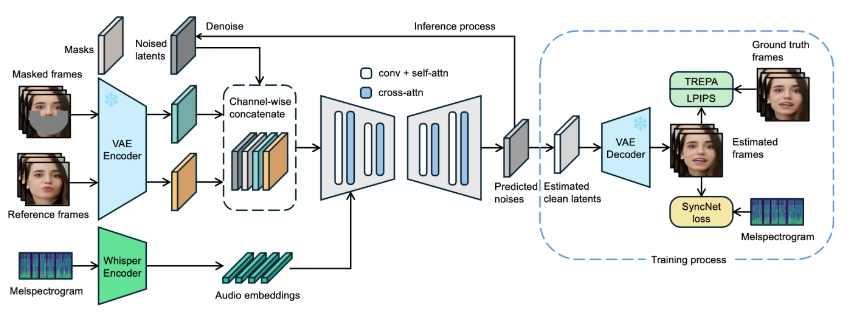
LatentSync是一种基于音频条件的潜在扩散模型的端到端口型同步框架,旨在实现真实的口型同步。这一方法不同于传统的基于像素空间扩散或两阶段生成的口型同步方法,省去了中间运动表示。LatentSync能够直接利用Stable Diffusion的强大功能,建模复杂的音频与视觉之间的关联。此外,该框架还提出了时间表示对齐(TREPA)技术,以增强时间一致性并保持口型同步的准确性。TREPA利用大型自监督视频模型提取的时间表示,将生成的帧与真实帧对齐,从而克服传统扩散方法在不同帧间的一致性问题。
使用场景
LatentSync主要应用于以下场景:
- 影视制作:能够自动将音频配音与演员的口型同步,助力视频后期制作的高效化。
- 游戏开发:在动画角色中创造更加生动的口型同步表现,提升玩家的沉浸感和游戏体验。
- 社交媒体:可以用于生成短视频、Vlog等,快速实现个性化的口型同步内容。
- 教育与培训:在语言学习和在线课程中,提供更真实的口语练习和示范环境。
- 虚拟试衣:为网络购物平台提供虚拟试衣时角色的真实口型表现,提升用户体验。
总之,LatentSync以其高效的口型同步能力,广泛适用于影视、游戏、社交媒体等多个领域。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621