
VisionReward
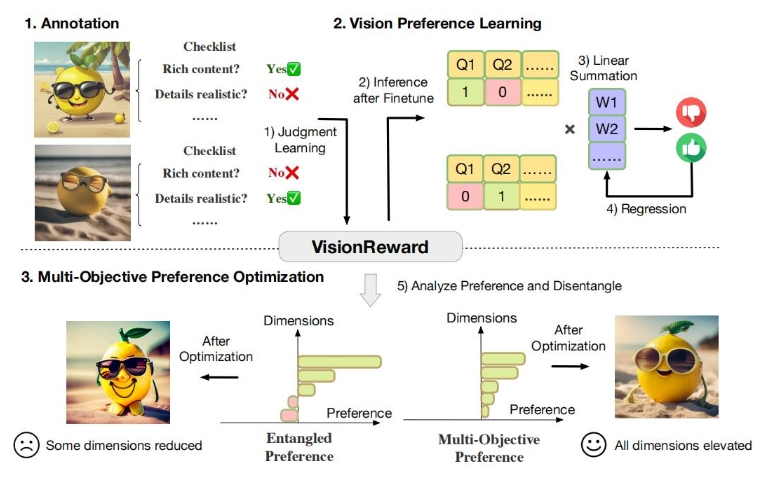
VisionReward是一个细粒度、多维度的人类偏好学习模型,旨在提高图像和视频生成的质量。该模型通过将人类的偏好分解为多个维度,每个维度由一系列判断问题组成,这些问题经过线性加权和求和,生成一个可解释且准确的分数。为了克服视频质量评估中的挑战,VisionReward系统地分析了视频的各种动态特征,使其在视频偏好预测上的表现超越了现有的VideoScore,提升了17.2%。
使用场景
- 图像和视频质量评估:VisionReward可以根据多维度的标准对图像和视频进行质量评分,帮助用户选择优质内容。
- 生成模型的优化:在图像和视频生成领域,VisionReward能够提供反馈,使生成模型根据人类的偏好进行优化,从而提高生成内容的质量。
- 内容比较:用户可以使用VisionReward来比较两个视频的优劣,从而选择更受偏好的版本。
- 用户交互与问答:模型支持对图像和视频通过问答的方式进行交互,允许用户基于给定的问题获取“是/否”的答复。
快速使用
用户可以通过安装依赖、下载预训练模型、进行质量评分、问答查询及视频比较等步骤来快速启动使用VisionReward。相关模型及数据集可在Hugging Face等平台上访问。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621