
Multimodal Open R1
Multimodal Open R1 简介
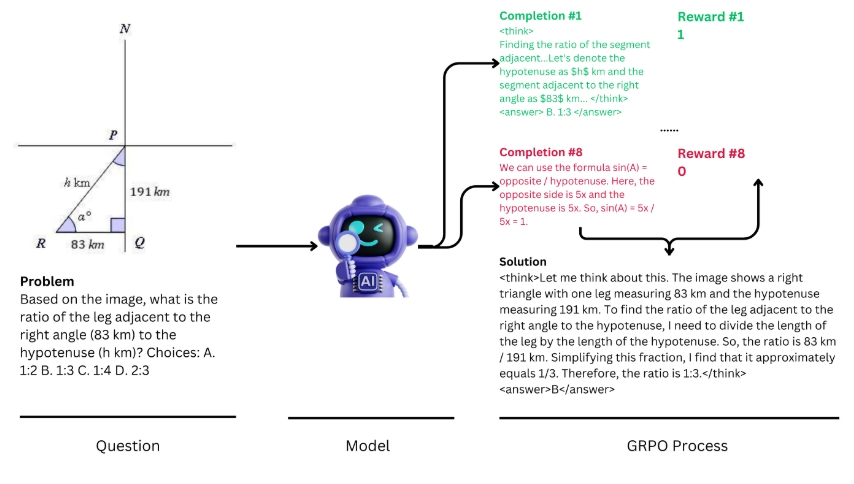
Multimodal Open R1 是一个针对多模态模型的研究和开发项目,致力于探索和实现基于 GRPO(Generalized Reinforcement Policy Optimization)算法的多模态强化学习(RL)模型。该项目主要以数学推理为主题,推出了首批 8,000 个多模态 RL 训练示例。这些数据由 GPT-4o 生成,包含推理路径和可验证答案,数据源于 Math360K 和 Geo170K。
项目的重要特性包括:
- 结合了多个现有的多模态模型如 Qwen2-VL 系列、Aria-MoE,基于 Hugging Face 的开源库进行实现。
- 提供了可公开访问的多模态数据集,并实时开放用户生成数据的脚本,使研究者能够自主探索数据的创建。
- 关注模型在多选题(MCQ)场景下的能力,讨论了如何确保模型的选择过程是有效的,以及如何改善模型的推理能力。
使用场景
- 教育领域:可以用于数学教育辅助工具,帮助学生通过多模态数据进行学习,提供即时反馈和推理路径。
- AI 辅助决策:在需要进行复杂推理的场景,如科学研究、工程设计等,Multimodal Open R1 可以帮助用户通过直观展示推理过程,辅助决策。
- 模型评估:研究人员可以利用该项目中的数据集对其多模态模型进行评估,检验模型的推理能力和准确性。
- 数据生成:为研究人员提供生成可验证的多模态 RL 数据的工具,促进对其他领域的 RL 数据集扩展和探索。
总体而言,Multimodal Open R1 为多模态学习和强化学习的研究提供了一个良好的基础,并鼓励社区反馈和合作,以进一步提升其应用价值和研究深度。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621